
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- sysstat
- ifconfig
- 우분투 22.04 패스워드 초기화
- 도커
- 도커 설치
- 리눅스 기본명령어
- A100
- Ubuntu 22.04
- TAIL
- ethtool
- docker
- python
- V100
- NGC
- uname
- nvidia
- 엔비디아 도커
- 우분투패스워드초기화
- grub
- 모니터링
- netplan
- TensorFlow
- 우분투
- 패스워드초기화
- sudoer
- Cat
- dmesg
- passwd
- CUDA
- nvidia-docker
- Today
- Total
또이리의 Server Engineer
리눅스 OS 점검 - 상태 파악 monitoring 본문
리눅스 OS 점검 - 상태 파악 monitoring
Linux 문제 해결, 상태 확인
리눅스 OS를 사용하는 시스템에 문제가 발생했다면, 어떤 부분을 우선적으로 확인해야 할까요? 이번 스토리는 지난 시간에 이어서 시스템의 상태, 활동을 확인할 수 있는 명령어에 대해서 알아보겠습니다.
일단 이번 스토리부터는 코드 블록을 사용하겠습니다. 저는 캡처가 편하다고 생각해서 계속 사용했지만, 제 스토리에서 명령어나 스크립트를 복사해서 사용하시는 분들은 코드 블록이 편하겠다 싶어서 이번 스토리부터 코드 블록을 사용하겠습니다.
이번 스토리에서는 간단한 linux OS 문제점 파악과 지난 스토리에서 설치했던 sysstat를 이용하여, sar와 iostat를 알아보겠습니다.
uptime
일단 업타임(uptime)을 알아보겠습니다.
리눅스 명령어에서 uptime은 접속된 사용자와 사용 중인 머신의 CPU 부하 상태를 볼 수 있습니다.
root@localhost:~# uptime
20:50:50 up 1 min, 2 users, load average: 0.16, 0.11, 0.04
root@localhost:~#맨 앞줄부터 현재시간과 부팅 이후 시간, 사용자의 수, CPU load average 1 min, 5 min, 15 min 순입니다.
CPU 로드는 0에서 1까지의 범위입니다. 1이면 100% 사용이라고 보시면 됩니다.
옵션을 한 번 알아보겠습니다.
root@localhost:~# uptime --help
Usage:
uptime [options]
Options:
-p, --pretty show uptime in pretty format
-h, --help display this help and exit
-s, --since system up since
-V, --version output version information and exit
For more details see uptime(1).
root@localhost:~# uptime -p
up 8 minutes
root@localhost:~# uptime -s
2020-11-12 20:49:09
root@localhost:~#옵션은 많지 않습니다.
-p와 -s를 볼 수 있습니다.
-p는 시스템의 부팅 이후 현재까지 운영된 시간입니다. pretty time입니다.
-s는 시스템이 부팅된 시간입니다.
간단하게 해당 서버가 며칠 동안 시스템이 운용되고 있으며, 현재 접속된 사용자의 수, 최근 시간별 CPU의 부하율을 확인할 수 있습니다.
dmesg | tail
root@localhost:~# dmesg | tail
[ 5.507032] audit: type=1400 audit(1605181754.410:6): apparmor="STATUS" operation="profile_load" profile="unconfined" name="/usr/bin/lxc-start" pid=724 comm="apparmor_parser"
[ 5.513618] audit: type=1400 audit(1605181754.418:7): apparmor="STATUS" operation="profile_load" profile="unconfined" name="/sbin/dhclient" pid=719 comm="apparmor_parser"
[ 5.513619] audit: type=1400 audit(1605181754.418:8): apparmor="STATUS" operation="profile_load" profile="unconfined" name="/usr/lib/NetworkManager/nm-dhcp-client.action" pid=719 comm="apparmor_parser"
[ 5.513620] audit: type=1400 audit(1605181754.418:9): apparmor="STATUS" operation="profile_load" profile="unconfined" name="/usr/lib/NetworkManager/nm-dhcp-helper" pid=719 comm="apparmor_parser"
[ 5.513621] audit: type=1400 audit(1605181754.418:10): apparmor="STATUS" operation="profile_load" profile="unconfined" name="/usr/lib/connman/scripts/dhclient-script" pid=719 comm="apparmor_parser"
[ 5.515808] audit: type=1400 audit(1605181754.418:11): apparmor="STATUS" operation="profile_load" profile="unconfined" name="/usr/bin/man" pid=734 comm="apparmor_parser"
[ 5.718760] NET: Registered protocol family 40
[ 5.869843] new mount options do not match the existing superblock, will be ignored
[ 5.928248] random: crng init done
[ 5.928249] random: 7 urandom warning(s) missed due to ratelimiting
root@localhost:~#dmesg는 지난 포스트에서 설명한 것과 같이 시스템 메시지를 확인할 수 있습니다. 부팅 이후 모든 커널 메시지가 출력되므로 tail을 이용하여 마지막 10 line을 출력합니다.
해당 메시지를 통해서 에러에 대한 단서를 찾을 수 있습니다. dmesg | more를 통해서 전체 메시지를 확인할 수도 있습니다. dmesg | grep -i를 통해서 특정 문자열을 검색할 수도 있습니다.
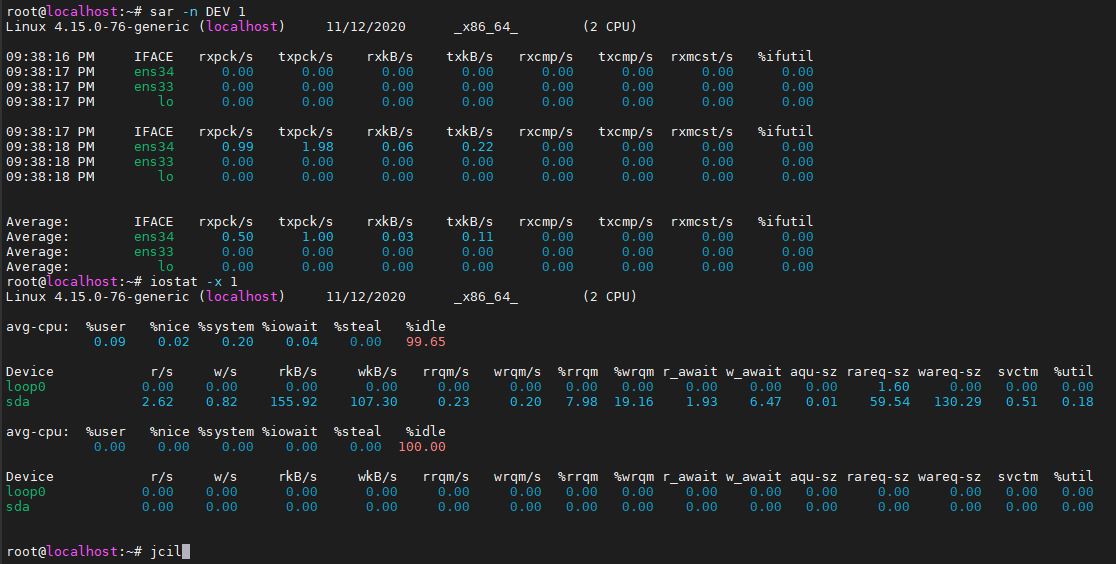
sar -n DEV 1
이번에는 sar에 대해서 알아보겠습니다.
- I/O 전송량-페이징-프로세스 개수
- 블록 디바이스 활동
- 인터럽트-네트워크 통계
- run 큐 및 시스템 부하 평균
- 메모리와 스왑 공간 활용 통계
- 메모리 통계
- CPU 이용률
- 특정 프로세스에 대한 CPU 이용률
- inode, 파일, 기타 커널 테이블에 대한 상태
- 시스템 스위칭 활동(context switch)
- 스와핑 통계
- 특정 프로세스 통계
- 특정 프로세스의 하위 프로세스 통계
- TTY 디바이스 활동
sar 명령어도 다양한 모니터링을 할 수 있습니다.
하지만 이번 스토리는 sar -n DEV 1을 사용해서 네트워크 디바이스를 확인하겠습니다.
끝에 숫자 1은 1초당 상태 확인입니다.
root@localhost:~# sar -n DEV 1
Linux 4.15.0-76-generic (localhost) 11/12/2020 _x86_64_ (2 CPU)
09:17:44 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
09:17:45 PM ens34 2.00 0.00 0.12 0.00 0.00 0.00 0.00 0.00
09:17:45 PM ens33 1.00 0.00 0.06 0.00 0.00 0.00 0.00 0.00
09:17:45 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: ens34 2.00 0.00 0.12 0.00 0.00 0.00 0.00 0.00
Average: ens33 1.00 0.00 0.06 0.00 0.00 0.00 0.00 0.00
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
root@localhost:~#IFACE: Network Interface 이름
rxpck/s: 초당 받은 패킷수
txpck/s: 초당 전송한 패킷수
rxbyt/s: 초당 받은 bytes
txbyt/s: 초당 전송한 bytes
rxcmp/s: 압축된 패킷을 초당 받은 수
txcmp/s: 압축된 패킷을 초당 전송한 수
rxmcst/s: 초당 받은 다중 패킷 수
네트워크의 활동 상태를 확인하기에는 가장 적합한 명령어입니다.
iostat -xz 1
iostat는 디스크의 입출력 통계 및 처리량, 대기 열등을 모니터링할 수 있습니다.
root@localhost:~# iostat
Linux 4.15.0-76-generic (localhost) 11/12/2020 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.11 0.03 0.25 0.06 0.00 99.56
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
loop0 0.00 0.00 0.00 8 0
sda 4.26 195.94 134.51 460993 316468
root@localhost:~# iostat -x
Linux 4.15.0-76-generic (localhost) 11/12/2020 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.11 0.03 0.25 0.06 0.00 99.56
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.60 0.00 0.00 0.00
sda 3.28 0.97 195.57 134.26 0.28 0.23 7.98 18.87 1.93 6.88 0.01 59.54 138.14 0.52 0.22
root@localhost:~# iostat -x 1
Linux 4.15.0-76-generic (localhost) 11/12/2020 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.11 0.03 0.24 0.05 0.00 99.57
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.60 0.00 0.00 0.00
sda 3.26 0.97 194.19 133.31 0.28 0.22 7.98 18.86 1.93 6.87 0.01 59.54 138.02 0.52 0.22
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
root@localhost:~#옵션 설명
-c : cpu 사용량 정보를 출력
-d : 디바이스의 사용량 정보를 출력
-k : 초당 블록수 대신 초당 Kb를 사용
-m : 초당 블록수 대신 초당 Mb를 사용
-t : 각 결과 앞에 시간을 포함해서 출력
-V : 마지막에 버전 숫자를 출력
-n : NFS(리눅스 공유 파일 시스템)의 사용량을 출력
-h : -n 옵션과 동일한 결과를 보여주지만 -n 보다는 가독성이 좋게 출력.
-p [ device | ALL ] : 블록 디바이스와 시스템에서 사용되는 모든 파티션 정보를 출력
디바이스 이름이 지정되면 해당 디바이스에서 사용하는 통계 정보를 제공
ALL을 붙여 사용하면 시스템에 정의된 모든 블록 디바이스와 파티션 정보를 한 번도 사용되지 않은 것도 포함하여 결과를 출력
-x : 보다 확장된 통계 정보를 출력 -n과 -p 옵션을 같이 사용할 수 없습니다.
r/s : 디바이스 초당 읽기 요청 건수
w/s : 디바이스 초당 쓰기 요청 건수
rrqm/s : 디바이스 큐 대기 중 초당 읽기 요청 건수
wrqm/s : 디바이스 큐 대기 중 초당 쓰기 요청 건수
rsec/s : 디바이스 초당 읽어들인 섹터 개수
wsec/s : 디바이스 초당 기록한 섹터 개수
avgrq-sz : 디바이스 요청 초당 평균 데이터 크기
avgqu-sz : 디바이스 요청 초당 평균 큐 길이
await : 디바이스 처리되기 위해서 요청된 I/O 평균 시간 (밀리초, 1/1000초)
큐에서 소요된 시간과 처리된 시간이 합산 출력
svctm : 디바이스 처리한 I/O 평균 시간 (밀리초, 1/1000초)
% util : 디바이스 요청한 I/O 작업을 수행하기 위해 사용한 CPU 시간 백분율
값이 100%에 수렴할수록 디바이스가 한계에 도달했다고 판단
이상 리눅스 OS 현 상태를 파악할 수 있는 명령어들을 알아보았습니다.
'Linux Engineer' 카테고리의 다른 글
| Python 3 install - 우분투 파이썬 3 설치 (1) | 2020.11.14 |
|---|---|
| 우분투 커널 확인 - 변경 및 삭제 (0) | 2020.11.13 |
| 우분투 스트레스 테스트 - 모니터링 (0) | 2020.11.11 |
| 우분투 18.04 엔비디아 도커 - 텐서플로우 설치 (0) | 2020.11.09 |
| Nvidia Tesla A100 - 8GPU error Xid 61 (0) | 2020.11.08 |



